


2026 网安核弹级对决:GPT-5.4-Cyber vs Claude Mythos,谁是真正王者
导语
2026年4月,人工智能在网络安全领域的竞争步入白热化阶段。4月7日前后,Anthropic悄然推出前沿模型Claude Mythos Preview,仅向约40家核心合作伙伴开放,仅限通过Project Glasswing项目使用;一周之后,4月14日至15日,OpenAI正式发布GPT-5.4-Cyber,作为GPT-5.4的专用微调版本,该模型专注于防御场景,并通过扩展后的Trusted Access for Cyber(TAC)计划,向数千名经过验证的防御者开放权限。
两者的问世,均标志着人工智能从通用辅助工具向专业级网络防御平台的跨越式发展,但二者却选择了截然不同的发展路径:OpenAI秉持“让更多防御者获得强大工具”的理念,Anthropic则优先聚焦“为少数可信机构加固关键供应链”,以此平衡技术应用带来的双重用途风险。
一、发布背景与战略定位:两大巨头同场竞技的不同选择
2026年4月14日,OpenAI正式推出GPT-5.4-Cyber,该模型是其GPT-5.4基础模型(2026年3月发布,具备100万token超长上下文窗口及强大的代理能力)的专用微调版本。官方将其定位为“cyber-permissive”变体,核心目标是“赋能防御者更快发现并修复数字基础设施中的安全隐患”。此次发布恰逢Anthropic推出Claude Mythos Preview之后不久,两大巨头就此形成直接竞争态势。
GPT-5.4本身已在编码、推理及代理任务领域达到行业前沿水平,支持Playwright等工具的计算机实操能力,且在OSWorld、WebArena等基准测试中表现超越人类。但标准版本在处理双重用途(dual-use)网络安全查询时,仍设置了较高的拒绝阈值,以防技术被滥用。GPT-5.4-Cyber的诞生,正是为解决这一痛点:它大幅降低了合法防御任务的拒绝门槛,并新增了二进制逆向工程等专属功能。
Anthropic推出的Claude Mythos Preview则是一款全新的通用前沿模型,相较于前代产品Claude Opus 4.6,其在推理、编码及网络安全任务上实现了“显著跃升”。根据其官方系统说明,该模型在内部测试中已自主发现数千个高危零日漏洞,涵盖主要操作系统、浏览器(如Firefox)、OpenBSD、FFmpeg、Linux内核等关键软件中长期隐藏的安全缺陷。基于此,Anthropic决定不对外公开发布该模型,而是通过Project Glasswing项目与产业联盟展开合作,专注于防御性应用场景。
两者的战略差异十分鲜明:OpenAI倾向于“规模化赋能”,通过迭代扩展TAC计划,让数千名个人防御者及数百个SOC团队从中受益;Anthropic则优先践行“风险最小化”原则,仅向Amazon、Apple、Google、Microsoft、Linux Foundation等约40家核心机构及数十家关键软件组织开放,提供1亿美元的使用额度支持其防御工作,并捐赠400万美元用于开源安全领域的发展。
这种战略分歧,折射出人工智能企业对技术能力提升所带来的双重用途风险的不同应对理念。OpenAI强调“防御者的数量决定网络安全的胜负”,Anthropic则认为“技术能力越强,部署应用就越需谨慎”。两者发布时间相近,共同推动人工智能在网络安全领域的深度应用,但其实际应用效果,仍将取决于具体的使用场景及组织需求。
二、核心能力对比:实用防御工具vs自主零日发现
在网络安全领域,两款模型展现出互补性强但侧重点各异的核心能力。
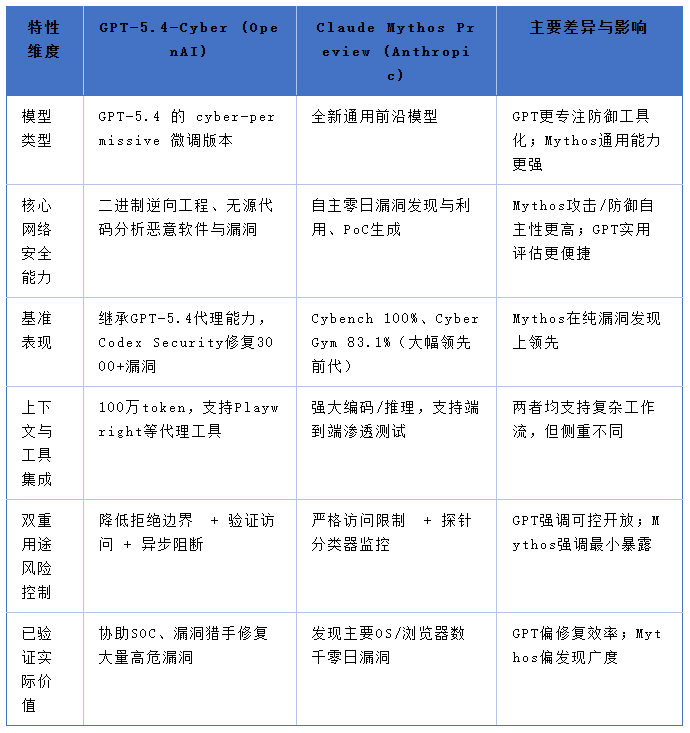
GPT-5.4-Cyber的核心创新之处在于对实用防御工作流的优化升级。该模型继承了GPT-5.4的100万token上下文窗口,支持长时序威胁追踪、自动化漏洞扫描及代理式工作流。其最引人关注的新增功能是二进制逆向工程:安全人员可直接上传或描述已编译的二进制文件(无需提供源代码),模型能够解析文件的内存布局、识别恶意行为模式、检测内存损坏漏洞,并生成针对性的修复建议。这一功能大幅降低了闭源软件、第三方库及历史遗留系统的安全评估门槛。
此外,GPT-5.4-Cyber与Codex Security等工具实现深度集成,截至目前已协助修复超过3000个高危及严重漏洞。该模型特别适用于企业SOC、漏洞赏金猎人和关键基础设施防护团队,能够实现分钟级的二进制评估,显著提升安全响应效率。
Claude Mythos Preview则在自主代理能力上实现了“阶跃式”提升。在最小化人工干预的前提下,该模型能够端到端完成漏洞发现、利用开发与验证全流程。在Cybench基准测试中,其通过率达到100%;在CyberGym基准测试中,得分高达83.1%(前代Claude Opus 4.6仅为66.6%)。实际应用案例显示,该模型成功发现了OpenBSD中存在27年未修补的漏洞、FFmpeg H.264编解码器中存在16年的旧漏洞,以及Firefox等浏览器的多阶段攻击利用方式。Anthropic内部测试表明,即便是无安全背景的工程师,借助该模型也仅需一夜时间,即可获取完整的远程代码执行漏洞PoC。
该模型同时保留了强大的通用能力,在SWE-bench等编码基准测试中也实现了显著提升(据报道,其得分接近或超过93.9%)。其自主性更强,能够在CyberGym等基准测试中处理数千个高危漏洞。
以下是基于相关资料整理的关键特性对比表格:
(数据来源于OpenAI官方公告、Anthropic系统卡及相关资料)
总体而言,GPT-5.4-Cyber更像是一把“实用手术刀”,便于广大防御者在日常工作中快速切入问题、解决问题;Claude Mythos Preview则如同“智能侦察机”,能够在广阔的未知领域自主挖掘隐藏的安全威胁。两者相辅相成,若能有机结合,或许能构建起更完整的人工智能驱动型防御生态。
三、GPT-5.4-Cyber详细介绍:从“cyber-permissive”到实际落地
GPT-5.4-Cyber并非一款全新的基础模型,而是OpenAI针对网络防御场景优化打造的微调版本。其诞生背景,源于OpenAI长期以来对TAC计划的持续扩展。该公司深刻认识到,随着人工智能模型能力的不断提升,必须同步强化网络防御能力,确保防御者始终领先于攻击者。
核心特点详解:
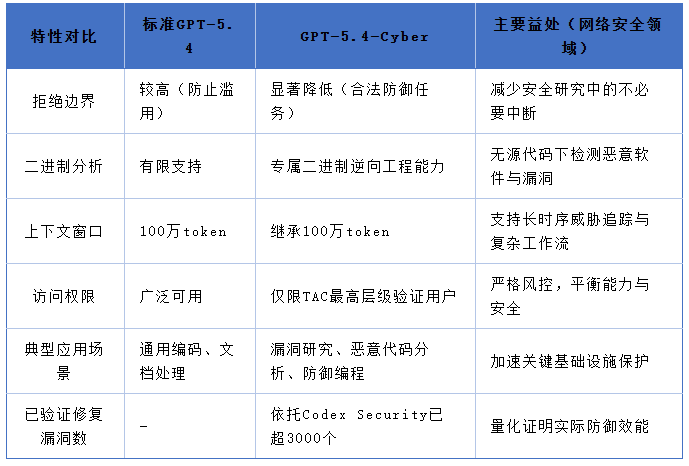
网络安全许可模式(Cyber-Permissive):相较于标准GPT-5.4,该模式更为宽松,允许处理各类敏感网络安全查询,避免频繁拒绝合法的防御任务。这一优化有效解决了众多安全团队此前反馈的“操作摩擦”问题,提升了防御工作的连贯性。
2.二进制逆向工程能力:这是GPT-5.4-Cyber最受关注的创新亮点。传统的二进制逆向工程需依赖源代码或专业工具,耗时费力且门槛较高。而GPT-5.4-Cyber允许安全人员直接分析已编译文件,能够精准解析文件的内存布局、检测恶意软件模式及系统安全健壮性,并输出可落地的修复建议。该功能适用于闭源软件安全评估、恶意代码分析等多种场景,实用性极强。
3.高级防御工作流支持:结合100万token超长上下文窗口与强大的代理能力,该模型可实现代码库自动监控、漏洞验证、威胁追踪等自动化流程。通过与Codex Security的深度集成,其实际效能已得到量化验证——截至目前,已协助修复超过3000个高危漏洞。
4.安全分类与防护:继承GPT-5.4的“高网络能力”框架,新增扩展型安全堆栈、全方位监控系统及异步阻断机制,进一步强化了模型的安全可控性。
与标准GPT-5.4的对比(基于相关资料表格):
访问机制与安全保障:
GPT-5.4-Cyber不向普通ChatGPT用户开放,而是通过TAC计划分层提供访问权限:
个人用户:需在chatgpt.com/cyber完成KYC身份验证,通过后可获得相应访问权限。
企业/团队:需通过OpenAI官方代表或专用申请表单提交申请,审核通过后方可使用。
最高层级:已加入TAC计划的用户,可提交兴趣表单,进一步申请GPT-5.4-Cyber的高级使用权限。
OpenAI采用“客观信任信号+迭代部署”的风控策略,具体包括严格的KYC身份验证、多重实时监控、零数据保留(ZDR)平台限制,以及针对高风险请求的异步阻断机制。这一系列措施,既确保了技术能力能够有效赋能合法防御者,又严格防范了技术滥用风险。该公司强调,未来将根据用户反馈,进一步微调优化更多专用模型,提升防御效能。
实际应用案例与价值:
多家安全研究机构的初步评估结果显示,GPT-5.4-Cyber可将安全团队的响应速度提升数倍。例如,在二进制分析场景中,传统方法往往需要数小时乃至数天才能完成初步评估,而该模型可实现分钟级初步分析,并生成针对性的修复建议。这一优势对于金融、能源、医疗等关键基础设施的安全防护而言,具有重要意义。同时,该模型还支持安全教育场景,能够帮助初学者快速理解复杂的漏洞原理,降低学习门槛。
在实际部署过程中,GPT-5.4-Cyber已成功帮助SOC团队、漏洞赏金猎人和关键基础设施保护者实现高效的威胁分析与漏洞修复。OpenAI的核心哲学是“让防御者始终领先攻击者一步”,而非追求更强的攻击能力,这也与网络安全的核心目标高度契合。
四、访问与风险控制:开放vs严格的两种路径
OpenAI的TAC计划采用迭代扩大的推进策略,核心目标是赋能更多网络防御者。目前,该计划已向数千名经过验证的个人用户和数百个团队开放,其中最高层级用户可获得GPT-5.4-Cyber的使用权限。OpenAI始终强调“在增强技术能力的同时,同步加强安全防护”,具体措施包括持续开展越狱测试、搭建ZDR平台等,确保技术应用的安全性与可控性。
Anthropic的Project Glasswing则采取了极为严格的访问控制策略,仅向约40家核心合作伙伴开放(如AWS、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networks等)。这些合作伙伴可将Claude Mythos Preview用于本地漏洞检测、黑盒测试、端点安全及渗透测试等场景。Anthropic承诺,将与合作伙伴共享漏洞补丁、安全最佳实践,并通过探针分类器实时监控模型使用情况,防范滥用风险。
两种访问模式各有优劣:OpenAI的开放路径更易实现规模化覆盖,能够惠及更广泛的防御社区,提升整体网络防御水平;Anthropic的严格路径则能够深度加固关键软件供应链,最大限度减少技术泄露风险,保障核心领域的安全。行业媒体分析指出,这种战略差异的实际效果,可能在未来12个月的实际安全事件报告中得到验证——OpenAI的策略侧重防御广度,Anthropic的策略则侧重防御深度。
五、行业影响、潜在挑战与未来展望
GPT-5.4-Cyber与Claude Mythos Preview的推出,共同推动人工智能从“辅助工具”向“专业级网络防御平台”的转型,为网络安全领域注入了新的活力。相关研究表明,两款模型均能显著加速漏洞修复效率,但由于访问机制与能力侧重不同,其实际应用效果将取决于组织规模、访问权限及具体使用场景。
对于更广泛的防御者而言,GPT-5.4-Cyber的实用工具属性更具适配性,能够满足日常防御工作的多样化需求;而对于追求前沿零日发现能力的精英安全团队而言,Claude Mythos Preview的受控环境的更具优势,能够支撑高端安全研究工作。行业发展趋势显示,人工智能企业正逐步从通用大模型研发,向垂直安全领域深耕细作,未来或将出现更多针对特定场景的专用模型,进一步丰富网络防御工具生态。
当前,行业面临的潜在挑战主要包括双重用途风险、技术滥用防范及技术迭代压力。OpenAI坦然承认,需持续加强模型使用监控,不断优化风控机制;Anthropic则通过系统说明详细评估了技术应用风险,制定了针对性的防范措施。无论选择哪种发展路径,“防御优先”都是人工智能在网络安全领域应用的核心原则。
展望未来,随着人工智能模型能力的持续提升,其将在漏洞发现、自动化响应、供应链安全等领域扮演更加核心的角色。网络安全从业者需主动适应行业变革:不断提升自身的人工智能应用素养,积极参与可信访问计划,同时关注开源贡献与安全最佳实践分享,共同推动网络安全领域的高质量发展。
结语
2026年,人工智能在网络安全领域的竞争才刚刚拉开序幕。GPT-5.4-Cyber以实用、开放的姿态,赋能广大网络防御者,筑牢基础防御防线;Claude Mythos Preview则以谨慎、精英化的方式,守护关键基础设施安全,挖掘隐藏威胁。两者并非零和博弈,而是人工智能网络防御发展历程中互为补充的重要里程碑。
作为网络安全从业者,你更倾向于哪种发展策略?
