


新旧势力再较量,数据库不需要投机
在新赛道、新兴细分市场中,数据库厂商的核心机会仍然是解决客户的业务问题,而不是过度关注拿奖、追逐技术时尚,成为市场的投机者。

图片来源pixabay
生成式AI技术变革,正驱使数据库厂商展开激烈竞争。
传统厂商长期占据主导地位,却也因云原生分布式数据库的冲击而有所动摇。当AI风暴再次搅动这个市场,数据库厂商纷纷调整数据战略,试图更加贴近企业客户使用AI的实际场景。新旧势力间的角逐,实际也让真实的客户加快享受到新时代红利。
在Databricks的案例库中流传着这样一个故事。来自中国的全球消费电子品牌安克创新,其数据团队曾遇到过一个棘手问题:受原有数仓的制约,无法对企业内部多个系统和应用数据进行统一治理,这导致团队将大量时间用于数据治理及相关的Devops落地,几乎没有时间挖掘更高价值的数据任务,比如用于支持生成式AI的创新。
安克创新用上了云湖仓,而针对这一产品的选型中,其团队放弃了Snowflake,而选择Databricks,其关键一点在于技术层面,前者并不符合团队对操作便捷性和基于同一平台实现数据、分析、AI创新的需求。而基于Databricks的云湖仓产品Delta Lake实现200TB数据的统一数据底座后,安克创新又陆续用上了Databricks的其他产品:通过Unity Catalog实现表格式数据访问,基于MLflow实现AI应用自动化流程编排。准备就绪后,安克创新数据团队终于有机会去探索大模型驱动下的代码检索、自动生成SQL、问答知识库等服务。
安克创新的选择背后,是以Databricks和Snowflake为首的两大数据分析与智能服务提供商所焦灼的领域——云湖仓。在表引擎、分析引擎、实时计算引擎、数据入湖工具、数据开发DataOps工具链、统一元数据管理等相关的引擎或组件,以及当下面向AI的大模型自研、AI数据库层面,各方都展开了尤为激烈的竞争,以抢占市场先机。
过去两年间,其实很多企业都在尝试生成式AI应用,但直至今天,我们仍没有看到真正能大规模推广到企业中的AI案例。其核心问题在于生成式AI应用始终存在不准确或不相关的推理结果,也就是常称的“幻觉”问题。而结合上述案例实践能够进一步理解,减少模型幻觉的重要方法之一,是引入企业内部知识库,提高生成准确性和边界,这往往需要在IT基础设施和数据集成的统一性上下功夫。
看似技术引领了市场变革,其实不然。数据库市场的变局,是发展到一定程度必然面对的,并且早已箭在弦上。
1990~2020,被反复锤炼的一个技术名词
理解数据库市场这一切变化,还要从“仓”与“湖”说起。
作为一款分析型数据库,数据仓库(Data Warehouse)的出现已有几十年的历程,最早可以追溯到20世纪60年代,并且随着近些年大数据技术的发展而不断升级。
20世纪90年代,在比尔·恩门(Bill Inmon)和拉尔夫·金博尔(Ralph Kimball)的推动下,数据仓库迅速发展。被誉为数据仓库之父的比尔·恩门在《构建数据库仓库》一书中给出其定义:一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
这在当时,是一项重大创新,包括能够支持更快的商业智能(当时还谈不上AI,更多是BI),能更高效地处理结构化数据等,也存在明显缺点,如缺乏对非结构化数据的处理能力,处理大量数据需要较长时间。但这一技术方案,基本满足了当时大量处于初创阶段的中小企业或客户团队,对于处理有限数据和分析的诉求。
直至21世纪初,大数据的兴起给传统数据仓库带来了挑战。这一挑战首先暴露在谷歌、雅虎等互联网公司内部:后端有大量的业务系统支撑,同时也有支持“海量”数据服务的平台架构,但在数据分析、商业智能等方面,一直在使用传统的数据库+数据仓库作为底层支撑。传统的数据仓库无法处理大量非结构化数据,一旦遇到业务流量洪峰,数据仓库就会出现瓶颈,持续扩容也显得捉襟见肘。

为了应对这一挑战,数据湖(Data Lake)的概念应运而生。
从核心目标上讲,数据湖与数据仓库都是用于数据分析,以便为组织提供洞察,辅助业务决策,但二者仍有区分。数据湖通常存储用于高级分析应用的各类大数据,而数据仓库则存储用于基本商业智能、分析和报告用途的常规交易数据。
2003年至2006年期间,谷歌相继发表文件分布式系统GFS、并行计算框架MapReduce和BigTable论文,这“三驾马车”奠定了大数据技术的基石,开启了大数据技术发展大幕。随后,Hadoop出现,它以HDFS分布式文件系统作为存储层,以MapReduce提供计算,为海量数据处理提供了一套全面的解决方案,并在雅虎的支持下,Hadoop生态发展迅猛。
2010年,Hadoop World大会上Pentaho公司创始人詹姆斯·迪克森(James Dixon)率先提出“数据湖”的概念,以解决当时数据仓库处理大数据时所面临的的性能瓶颈。他指出:“如果把数据集市想象成一个瓶装水仓库,经过清洁、包装和结构化处理,方便饮用,那么数据湖就是一个更自然状态的大型水库。数据湖的内容从源头入湖,用户可来湖中查看、潜入或取样。”
也就是说,数据湖一开始就将所有数据源的数据进行存储,包括离线的、在线的,结构化的、非结构化的,各类面向事务型的数据。同时,利用Hadoop等大数据处理技术,使得海量数据处理更容易。
从理论上讲,数据湖的出现在很大程度是符合时代的,并且在2015年得到比较大的发展。但由于许多企业构建数据湖的进展并没有想象中顺利,也一定程度上削弱了数据湖的普及。例如,当时的数据湖只解决存储问题,分析计算的问题依然需要数仓完成,放到今天,计算、存储是需要同时被解决的。另外,数据湖的实施和维护成本高,且需要经年累月与企业业务流程以及数据分析工具集成,才能实现其价值。
那么,能否实现“仓”、“湖”的优点兼具?即让数据仓库直接ETL数据湖里的数据,实现湖、仓的打通。2020年,Databricks公司对湖仓一体(DLH,Data Lakehouse)概念的提出,不仅让Databricks这家以开源Spark出名的公司再次出圈,也让业内看到了湖仓一体架构的优越性,众多数仓专家由此也开始了对数据湖功能兼容的大量技术探索。
谁在入局
Databricks首先在2020年发表了一篇重要论文《A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics》,将“湖仓一体”作为一种新颖的数据管理方法。据论文描述,该方法将数据仓库和数据湖整合到一个系统中,以更“湖仓一体”的方式运行,充分利用云存储服务的成本效益,这尤其对于同时使用BI工具和依赖数据科学/机器学习解决方案的大型企业有益。
在概念提出的最开始一段时间,确实只有Databricks一家商业公司提供湖仓产品,但很快,随着湖仓一体理念得到广泛关注,围绕湖仓的技术组件和产品方案,逐渐衍生出四股力量:
一是MPP数据库Teradata和基于Hadoop的Cloudera等老牌公司,二是三大云厂商的同类产品包括Google BigQuery、Amazon Redshift、Azure Synapse Analytics;三是主打存算分离的云数仓(CDW)新贵Snowflake,四是以数据湖开源表格式Delta Lake、Apache Hudi等为基础的商业公司Databricks。
从技术路径上,与单独建仓或单独建湖的不同的是,前者无法保证数据湖与数据仓库中的数据一致性问题,湖仓一体是以数据仓库中支持数据湖特性,和以数据湖中支持数仓特性两大方向。例如,Snowflake、Amazon Redshift,以及国内的阿里云MaxCompute以前者为技术路径;而Databricks、Uber则以后者为技术路径。作为湖仓一体概念的提出者,Databricks如今基于Apache Spark、Delta Lake、MLflow等开源组件构建了相对完整的产品方案,并且基于三方云平台,将湖仓产品集成售卖。
数据湖、数据仓库曾各自独立发展过一段时间,现如今,这两个技术方案已经走向融合。
根据Fortune Business Insights公布的《大数据分析市场报告,2021-2028年》,目前大量初创公司正在争夺全球大数据分析市场的份额,预计2028年将达到5497.3亿美元。根据资本流动趋势和观察到的客户需求,大数据分析市场中最热门的领域无疑是数据仓库、数据湖、数据湖仓、数据网格、DataOps和超快速大数据查询引擎。
中国信通院《数据库发展研究报告(2024)》指出,随着智能时代的到来,AI大模型需要的存储底座需要具备高存储密度、高性能计算、数据安全保障等特点,能够对大规模数据进行高性能处理的湖仓一体技术成为AI大模型不可或缺的数据基础设施。原因在于两点:一是湖仓一体的设计为大模型提供了高性能数据处理底座,二是人工智能也使得仓内智能成为可能。
如果说传统数仓、数据湖能够向湖仓一体架构持续演进,其首要原因还是来自实际企业应用场景中,业务驱动的结果。那么,随着企业应用场景逐步推进到以AIGC的业务和应用中,AI大模型在企业的快速推进正客观促成湖仓相关领域的厂商展开竞赛,笔者注意到,各股势力不光频繁展开性能拉练,也在试图通过技术收购整合、投入研发,企业客户也成为这场竞赛中的直接受益者。
过去一年,头部的数据库企业,甚至于大模型企业都已经在积极采取产品发布、或进行收购、合作的方式,抢占AI大模型时代的先机。
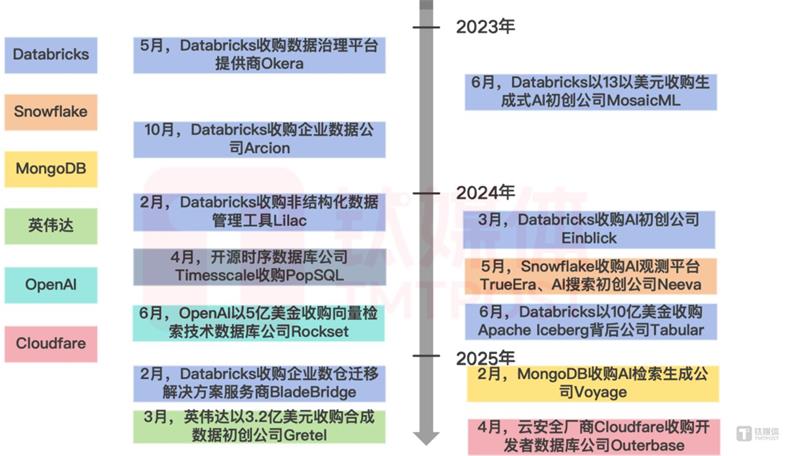
今年2月,Databricks公司还宣布与SAP达成合作,SAP将把Databricks的AI数据管理工具集成到其新的业务数据云;而Snowflake宣布将与英伟达合作,为企业量身定制AI模型。
另外,在大模型技术爆发背景下,以及各方产业链上下游厂商的频繁较量中,战火也早已烧到了中国市场。
以阿里云湖仓架构为例,在数据存储层,基于数据平台、数仓和数据湖能力基础之上,进行仓内数据模型直接调用;在数据服务层,提供RAG服务、Data API及模型管理能力;在场景应用层,湖仓可支持企业快速搭建知识库。
国内市场,除了阿里云、华为云等云厂商外,星环科技、滴普科技、柏睿数据、偶数科技等创业厂商也在过去一段时间展开了对湖仓一体架构的技术探索与产品落地。
但对比了品牌、产品技术、市场资源、客户基础、组织能力等多维度优势后,我们注意到,在湖仓领域,始终有两个无法忽视的竞对:Databricks和Snowflake。
两种路线的较量
其实两方势力的竞争成功与否,并不在于一地之得失,而在于有生力量之消长。Databricks与Snowflake竞争的背后,也是两种技术路线的较量。
与外界现如今感知所不同的是,湖仓这一概念在被市场得到关注之前,Databricks其实定位于基于Apache Spark构建的统一数据和分析平台,并且一直在缓慢且成功地发展其业务。只是在近些年,Databricks开始从Snowflake等数仓厂商手中夺取了越来越多的市场份额。
而Databricks的最大亮点在于,它是以流数据处理为出发点,向上扩展自身AI能力,向下打造湖仓一体,通过不断完善AI基础架构,为最上层AI应用提供一个优化的承载平台。因而Databricks并非是一家数仓或数据库公司,而是构建AI infra的公司。
业务层面,Databricks更专注于高级分析和处理复杂的数据处理任务,通常涉及数据科学或机器学习。这也使得Databricks一开始合作的客户通常具备数据工程能力,并认可其数据湖中支持数仓特性的技术路线。
技术层面,Databricks做了许多能力建设。首先,Databricks对其数据湖表格式开源项目Delta Lake投入了大量资金和,并且还是该开源项目的最大贡献者。
2024年,Databricks进一步收购Iceberg的商业公司Tabular,进一步巩固其市场地位,要知道Snowflake、Cloudera、AWS、Oracle、Salesforce等众多厂商基于Iceberg构建。这一操作明显使Snowflake的处境更加艰难,并导致其不得不宣布将Polaris Catalog作为Delta Lake和Iceberg的直接开源替代方案,以对抗Databricks的影响。
其次,Databricks成功解决了跨各种数据处理引擎的无缝互操作性这一重大挑战,消除了供应商锁定的问题。
此外,Databricks从一开始就面向数据科学、人工智能领域持续探索,并构建了一系列数据与AI工具组件。如开发和维护AI生命周期管理开源平台MLflow,用于进行机器学习模型的部署和训练;数据分析工具Koalas,可让使用Pandas进行编程的数据科学家直接切换到Spark上,用于大型分布式集群应用。
2023年,Databricks开源了其首个大语言模型dolly 2.0,为其后续推出大模型拉开了序幕。2023年末,Databricks以13亿美金收购大模型初创公司Mosaic,以便Databricks现有的客户实现数据源无缝集成,提高构建数据服务的统一体验。通过对MosaicML的技术和团队整合,MosaicML被全面整合进Databricks的湖仓产品中。
今年3月,Databricks发布了一款132B混合专家模型DBRX,该大模型由内部Mosaic Research团队开发,其人员一部分就来自于此前对MosaicML团队的收编而来。据Databricks透露,DBRX完全基于Databricks平台开发,利用Unity Catalog等工具进行数据治理、Apache Spark进行数据处理以及Mosaic AI Training进行模型训练和微调。正是这种深度集成,客户可以通过API访问DBRX,从而无缝集成到现有工作流程和应用程序中。
从趋势上看,随着生成式AI应用的出现,市场需求显然已经在从数仓转向了更有利于Databricks的湖仓技术。Databricks近期指出,已经有200多家客户从Snowflake迁移到Databricks,其中有8家还是头部大客户。
另一个信号是,Databricks和Snowflake之间的差距正在缩小。Databricks宣布预计截至2025年1月31日第四季度的收入运行率将超过30亿美元,而Snowflake公布的2025财年产品营收实现35亿美元。
Databricks已多次与Snowflake进行性能大战。2023年,为了甩开膀子撕逼,双方甚至同意将DeWitt条款限制拿掉,即允许研究人员和科学家在学术论文中明确使用其系统名称。
技术层面,Snowflake针对结构化数据的存储和分析进行了优化,并高度重视数据仓库的易用性和可扩展性。同时,Snowflake从2022年相继收购了Applica、Streamlit、SnowConvert、Myst.AI和Neeva等多家AI与数据领域初创公司,加大对AI分析和数据平台的投入。今年4月,Snowflake发布了其开源大模型Arctic,以4800亿参数MoE架构试图击败Databricks的DBRX。此外,Snowflake还与Anthropic等大模型厂商合作。去年10月,Snowflake还与Cloudera实现集成,客户通过使用Snowflake的计算引擎和获得Iceberg支持的Cloudera湖仓一体架构,实现动态扩展分析与AI工作负载,同时降低成本。
与Snowflake同样技术路线的云厂商也开始频繁向外界证明,其核心产品能够跟上生成式AI和大模型的进步。
Google BigQuery为解决湖仓统一治理,直接将治理功能嵌入到数仓中,而非单独工具或流程。近日的Google Cloud Next大会上,谷歌表示Google BigQuery自2011年面世以来,其客户数量已经是Snowflake和Databricks的五倍。

2024 Gartner云数据库管理系统魔力象限
无论走哪种技术路径,无非是代表不同的商业利益群体,这种争论对于客户而言,都需要深入了解当前和未来的需求。可能某些场景下,Databricks更广泛的功能使其更具优势,而在其他情况下,Snowflake的易用性亦会成为其决定性因素。
暗流涌动
但最耐人寻味的,是双方在AI大模型时代达成的某些共识对整个数据库市场的震动。当其他老牌对手看到Snowflake和Databricks增强了对大模型的支持,也终于下场布局,新兴的初创公司也因数据库市场的搅动,开始重新找准市场定位。
不久前,Snowflake、Databricks竞相展开对AI RAG(检索增强生成)公司VoyageAI的收购。收购Voyage或将帮助前者提升自身平台的速度和性能。例如,Snowflake已通过一项云服务向客户提供Voyage模型的访问权限,客户可以使用该服务构建AI应用。Databricks此前也在努力为其相应的服务提供同样的访问权限。不过,随着MongoDB对VoyageAI的成功截胡,一切正朝着新的变局演变。
与此同时,新兴AI搜索初创公司Glean已经在瞄准这块市场,推出能够帮助企业更有效搜索数据库中数据的产品。值得关注的是,近期Databricks还被曝出拟将收购无服务器初创公司Neon。
但更大的问题是,对于客户而言,企业对数据的诉求早已不在于记录信息、收集信息,更在于获得可行的见解,做出更明智、更快速的决策。在AI应用潮流和企业降本增效的驱使下,客户仍然需要花一定的精力和成本来做新数据库的尝试和迁移,同样面临极大风险。
数据库赛道也越来越卷了,尤其在国内市场,很多两三年前出现的初创公司或产品已消弭不少,诸多创业十年以上的数据库厂商也在频繁跟进技术基调更新产品。
而纷争角逐的核心主线是,在新赛道、新兴细分市场中,数据库厂商的核心机会仍然是解决客户的业务问题,而不是过度关注拿奖、追逐技术时尚,成为市场的投机者。(本文首发于钛媒体APP,作者|杨丽,编辑|盖虹达)
