


用3072个GPU,训练一万亿参数的模型
最近,橡树岭国家实验室的研究人员在Frontier超级计算机上训练了ChatGPT大小的大型语言模型(LLM),只需要37,888个GPU中的3,072个即可完成。该团队发表了一篇研究论文,详细介绍了它如何实现这一壮举以及在此过程中面临的挑战。
Frontier超级计算机配备了9,472个Epyc 7A53 CPU和37,888个Radeon Instinct 37,888 GPU。然而,该团队仅使用3,072个GPU来训练一个具有1万亿个参数的LLM,并使用1,024个GPU来训练另一个具有1,750亿个参数的LLM。
该论文指出,训练如此大型的LLM的关键挑战是所需的内存量,至少需要14 TB。这意味着需要使用多个具有64GB VRAM的MI250X GPU,但这引入了一个新问题:并行性。在法学硕士中使用更多GPU需要更好的沟通,才能真正有效地使用更多资源。否则,大部分或全部额外的GPU马力都会被浪费。
该研究论文深入探讨了这些计算机工程师究竟是如何做到这一点的细节,但简短的版本是,他们在Megatron-DeepSpeed和FSDP等框架上进行了迭代,改变了一些东西,以便训练程序在Frontier上运行得更优化。最后,结果非常令人印象深刻——微弱的扩展效率为100%,这基本上意味着随着工作负载大小的增加,尽可能高效地使用更多GPU。
与此同时,1750亿参数的LLM的强扩展效率略低,为89%,1万亿参数的LLM的强扩展效率为87%。强扩展是指在不改变工作负载大小的情况下增加处理器数量,根据阿姆达尔定律,这往往是更高的核心数量变得不太有用的地方。考虑到他们使用的GPU数量,即使87%也是一个不错的结果。
然而,该团队指出在Frontier上实现这种效率存在一些问题,并表示“需要做更多的工作来探索AMD GPU上的高效训练性能,而且ROCm平台很少。”正如论文所述,大多数这种规模的机器学习都是在Nvidia的CUDA硬件软件生态系统内完成的,相比之下,AMD和英特尔的解决方案还不够成熟。当然,此类努力将促进这些生态系统的发展。
世界上最快的超算——Frontier
尽管如此,世界上最快的超级计算机仍然是Frontier,它配备了全AMD硬件。
AMD驱动的Frontier超级计算机现在是世界上第一台官方认可的百亿亿次超级计算机,在持续Linpack运行期间达到了1.102 ExaFlop/s。它在新发布的全球最快超级计算机Top500榜单中名列第一,今年榜单上采用AMD技术的系统数量大幅增加。Frontier不仅超越了前任领导者日本Fugaku,而且将其击败——事实上,Frontier的速度比榜单上接下来的七台超级计算机的总和还要快。值得注意的是,虽然Frontier在持续的Linpack FP64基准测试中达到了1.1 ExaFlops,但该系统在峰值性能下可提供高达1.69 ExaFlops,但在更多调整后还有达到2 ExaFlops的空间。
作为参考,1 ExaFlop等于每秒1万亿次浮点运算。
Frontier现在也被列为地球上最快的AI系统,在HPL-AI基准测试中提供6.88 ExaFlops的混合精度性能。这相当于大脑中860亿个神经元中的每一个每秒执行6800万条指令,凸显了其强大的计算能力。看来该系统将与新推出的人工智能超级计算机(由Nvidia基于Arm的Grace CPU超级芯片提供支持)争夺人工智能领导地位。
此外,Frontier测试和开发(Crusher)系统也在Green500中名列第一,这表明Frontier的架构现在也是世界上最节能的超级计算架构(Frontier主系统在Top500中排名第二)。在资格基准测试运行期间,整个系统每瓦提供52.23 GFlops,同时消耗21.1 MW(兆瓦)功率。在高峰利用率时,Frontier消耗29兆瓦。
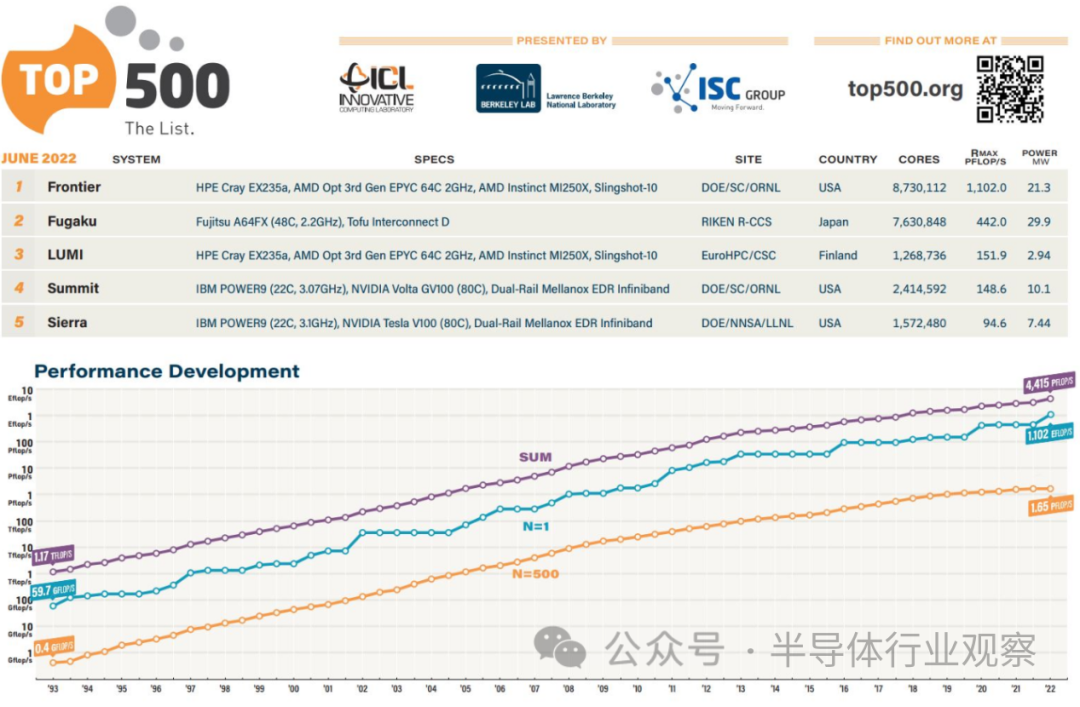
Frontier超级计算机的规模之大令人惊叹,但这只是AMD在今年Top500榜单中取得的众多成就之一——全球排名前10的超级计算机中,有5台采用AMD EPYC(霄龙)系统,而排名前20的超级计算机中,有10台采用AMD EPYC(霄龙)系统。事实上,AMD EPYC(霄龙)现已出现在全球Top500超级计算机中的94台中,比2021年11月列出的73台系统和2021年6月列出的49台系统稳步增长。AMD也出现在超过一半的新系统中。今年的名单。正如您在上面的相册中看到的那样,Intel CPU仍然占据了Top500中的大多数系统,而Nvidia GPU也仍然是占主导地位的加速器。
然而,在能效方面,AMD在最新的Green500榜单中占据了主导地位——该公司为全球四种最高效的系统提供支持,并且在前10名中占有8个席位,在前20名中占有17个席位。
Frontier超级计算机由HPE制造,安装在美国能源部(DOE)位于田纳西州的橡树岭国家实验室(ORNL)。该系统拥有9,408个计算节点,每个节点配备一个64核AMD“Trento”CPU,搭配512 GB DDR4内存和四个AMD Radeon Instinct MI250X GPU。这些节点分布在74个HPE Cray EX机柜中,每个机柜重8,000磅。总而言之,该系统拥有602,112个CPU内核,与4.6 PB DDR4内存相关联。
此外,37,888个AMD MI250X GPU具有8,138,240个内核,并拥有4.6 PB的HBM内存(每个GPU 128GB)。CPU和GPU使用基于以太网的HPE Cray Slingshot-11网络结构连接在一起。整个系统使用直接水冷来控制热量,350马力的泵将6,000加仑的水输送到系统中-这些泵可以在30分钟内注满一个奥林匹克规模的游泳池。系统中的水运行温度为85度,温暖宜人,这有助于提高能源效率,因为系统不使用冷却器来降低水温。
整个系统连接到一个具有700 PB容量、75 TB/s吞吐量和150亿IOPS性能的高性能存储子系统。元数据层分布在480个NVMe SSD上,提供10PB的总容量,而5,400个NVMe SSD为主高速存储层提供11.5PB的容量。同时,47,700个PMR硬盘提供679PB的容量。
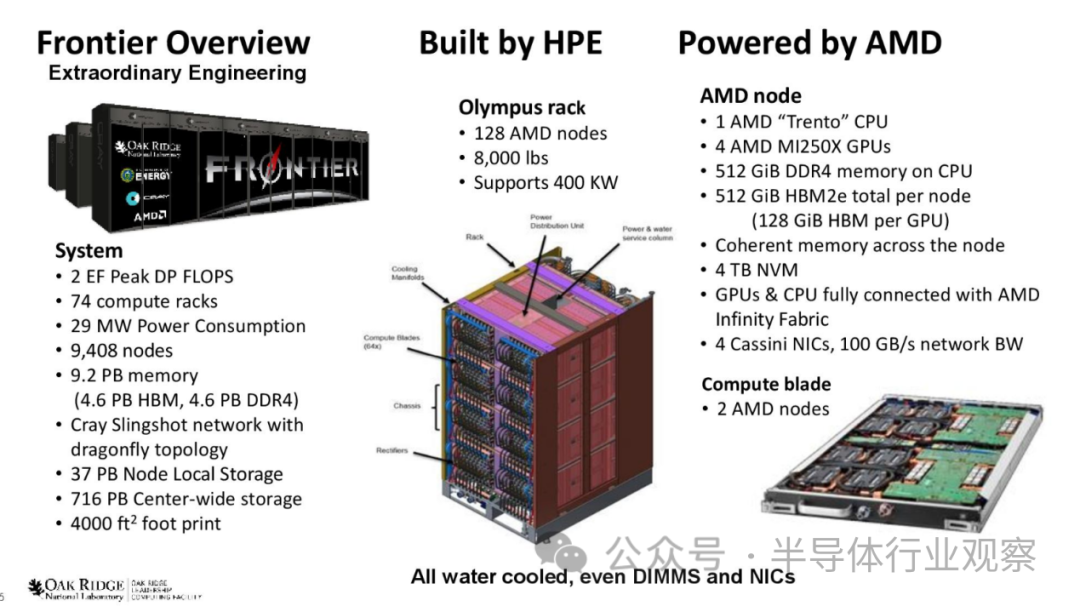
组装Frontier本身就是一个挑战,因为ORNL必须采购6000万个具有685个不同零件编号的零件来构建该系统。施工期间芯片短缺,影响了其中167个零件,因此ORNL发现自己短缺200万个零件。AMD也遇到了问题,因为其MI200 GPU的15个部件号出现短缺。为了帮助避免短缺,橡树岭国家实验室与ASCR合作,获得了这些零部件的国防优先和分配系统(DPAS)评级,这意味着美国政府由于Frontier对国防的重要性而援引《国防法》来采购这些零部件。
尽管该系统目前的峰值功率为29 MW,但Frontier的机械设备可以冷却高达40 MW的计算能力,相当于30,000个美国家庭的冷却能力。该工厂可扩展至70 MW,为未来的增长留出空间。
目前,Frontier正式成为世界上最快的超级计算机,也是第一个正式突破百亿亿次障碍的超级计算机。
AMD的下一个目标是什么?El Capitan是一台2+ExaFlop机器,最后一次上线是在2023年。建成后,这台Zen 4驱动的超级计算机将与英特尔驱动的Aurora争夺Top500中最快超级计算机的称号。
排名第二的是Aurora,其纯英特尔硬件(包括GPU),尽管目前只有一半用于基准测试提交。Nvidia GPU为第三快的超级计算机Eagle提供动力。如果AMD和英特尔想要保持这种排名,这两家公司将需要赶上英伟达的软件解决方案。
内容由半导体行业观察编译自tomshardware。
